Qi Feng, Hubert P.H. Shum, Shigeo Morishima
In IEEE Conference on Virtual Reality and 3D User Interfaces (IEEE VR), 2022
Overview
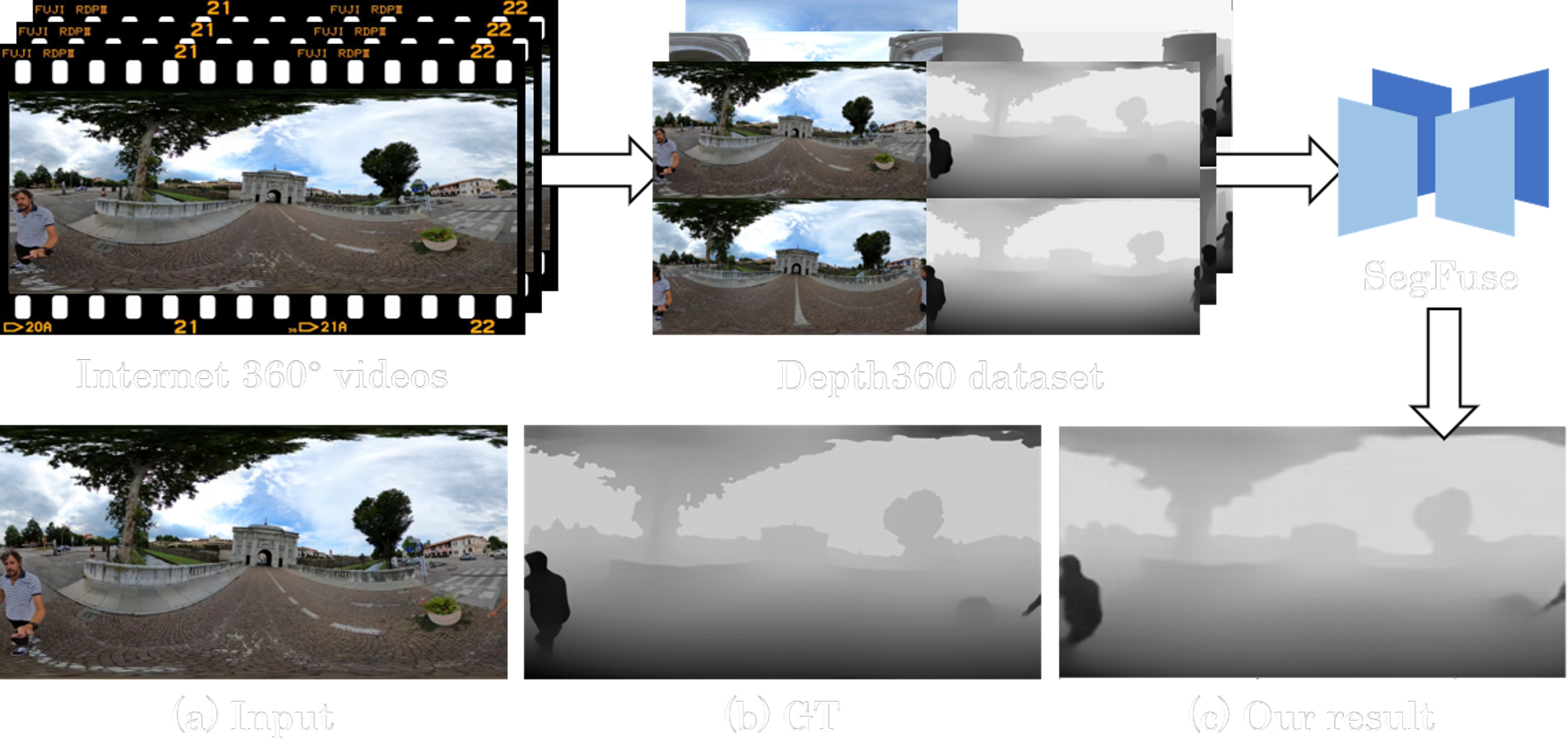
Figure 1. We present a method for generating large amounts of color/depth training data from abundant internet 360 videos. After creating a large-scale general omnidirectional dataset, Depth360, we propose an end-to-end two-branch multitasking network, SegFuse to learn single-view depth estimation from it. Our method shows dense, consistent and detailed predictions.
Abstract
Single-view depth estimation from omnidirectional images has gained popularity with its wide range of applications such as autonomous driving and scene reconstruction. Although data-driven learning-based methods demonstrate significant potential in this field, scarce training data and ineffective 360 estimation algorithms are still two key limitations hindering accurate estimation across diverse domains.
In this work, we first establish a large-scale dataset with varied settings called Depth360 to tackle the training data problem. This is achieved by exploring the use of a plenteous source of data, 360 videos from the internet, using a test-time training method that leverages unique information in each omnidirectional sequence. With novel geometric and temporal constraints, our method generates consistent and convincing depth samples to facilitate single-view estimation.
We then propose an end-to-end two-branch multi-task learning network, SegFuse, that mimics the human eye to effectively learn from the dataset and estimate high-quality depth maps from diverse monocular RGB images. With a peripheral branch that uses equirectangular projection for depth estimation and a foveal branch that uses cubemap projection for semantic segmentation, our method predicts consistent global depth while maintaining sharp details at local regions. Experimental results show favorable performance against the state-of-the-art methods.
Results

Figure 2. Qualitative results of the proposed method. Our method generates globally consistent estimation and sharper results at local regions. Detailed comparisons with state-of-the-art can be found in the paper.
Depth360 Dataser (v1)
The Depth360 dataset includes 30000 pairs of color and depth images generated with the test-time training method described in the paper.
Considering the copyright issue raised by the reviewers, we are currently working on replenishing a part of the original dataset that were not licensed by creative commons. We expect to start distributing the dataset by first half of June.
Source Code
View on GitHub
1 | git clone https://github.com/HAL-lucination/segfuse.git |
Citations
1 | @INPROCEEDINGS{9756738, |
Acknowledgements
We appreciate the anonymous reviewers for their valuable feedback. This research was supported by JST-Mirai Program (JPMJMI19B2), JSPS KAKENHI (19H01129, 19H04137, 21H0504) and the Royal Society (IES\ R2\ 181024).